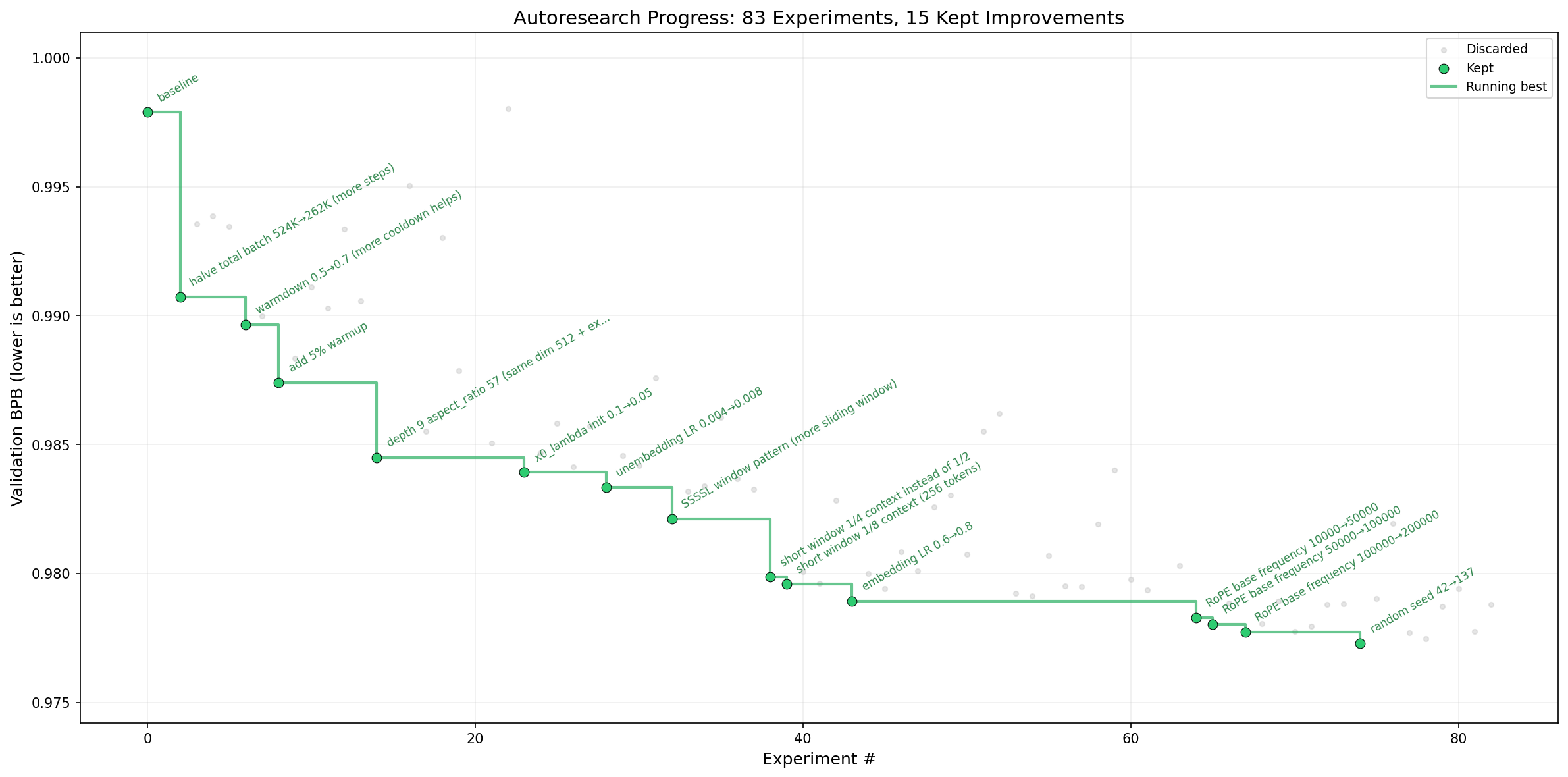
 |
| Figure 1: Progress of the autoresearch agent in training variants of nanochat. Extracted from [1]. |
John Schulman (Thinking Machines) on this blog argues, backed by careful experiments, that LoRA RL fine-tuning can match full-parameter RL fine-tuning. His intuition comes from the fact that in common reinforcement learning from verifiable rewards (RLVR) settings the total number of bits fed to the learner is small, so you don’t need to move all base weights to absorb the signal. In particular, he writes:
Self-supervised learning has been a game-changer for training large-scale Vision Transformers (ViTs), allowing models to learn powerful visual representations without human-provided labels. However, popular methods like DINO and iBOT suffer from a curious problem: as they train longer, their ability to handle dense, local tasks degrades, even as their global performance improves. This phenomenon, known as feature degradation, is characterized by noisy patch similarity maps and an over-alignment of patch features with the global CLS token.
In this post, we will see how to load a video using PyTorch, followed by a rant on how we perfom evaluations of video models. We will try various methods to load a video and convert it to a PyTorch tensor. These include VideoClips (from torchvision), torchvision.IO (using PyAV), and decord, my own implementation using ffmpeg and FFCV. We will use the Kinetics-400 dataset as an example. You can find the dataset here. All the code is available in this repository. I modified FFCV to be able to handle videos, you can find the fork here.
Some links and papers that I have found interesting this week. If you have any comments, please let me know.