ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
Jefferson Hernandez1, Ruben Villegas2, Vicente Ordóñez1,
1Rice University, 2Google DeepMind
Abstract
We propose ViC-MAE, a model that combines both Masked AutoEncoders (MAE) and contrastive learning. ViC-MAE is trained using a global featured obtained by pooling the local representations learned under an MAE reconstruction loss and leveraging this representation under a contrastive objective across images and video frames. We show that visual representations learned under ViC-MAE generalize well to both video and image classification tasks. Particularly, ViC-MAE obtains state-of-the-art transfer learning performance from video to images on Imagenet-1k compared to the recently proposed OmniMAE by achieving a top-1 accuracy of 86% (+1.3% absolute improvement) when trained on the same data and 87.1% (+2.4% absolute improvement) when training on extra data. At the same time ViC-MAE outperforms most other methods on video benchmarks by obtaining 75.9% top-1 accuracy on the challenging Something something-v2 video benchmark . When training on videos and images from a diverse combination of datasets, our method maintains a balanced transfer-learning performance between video and image classification benchmarks, coming only as a close second to the best supervised method.
Overview
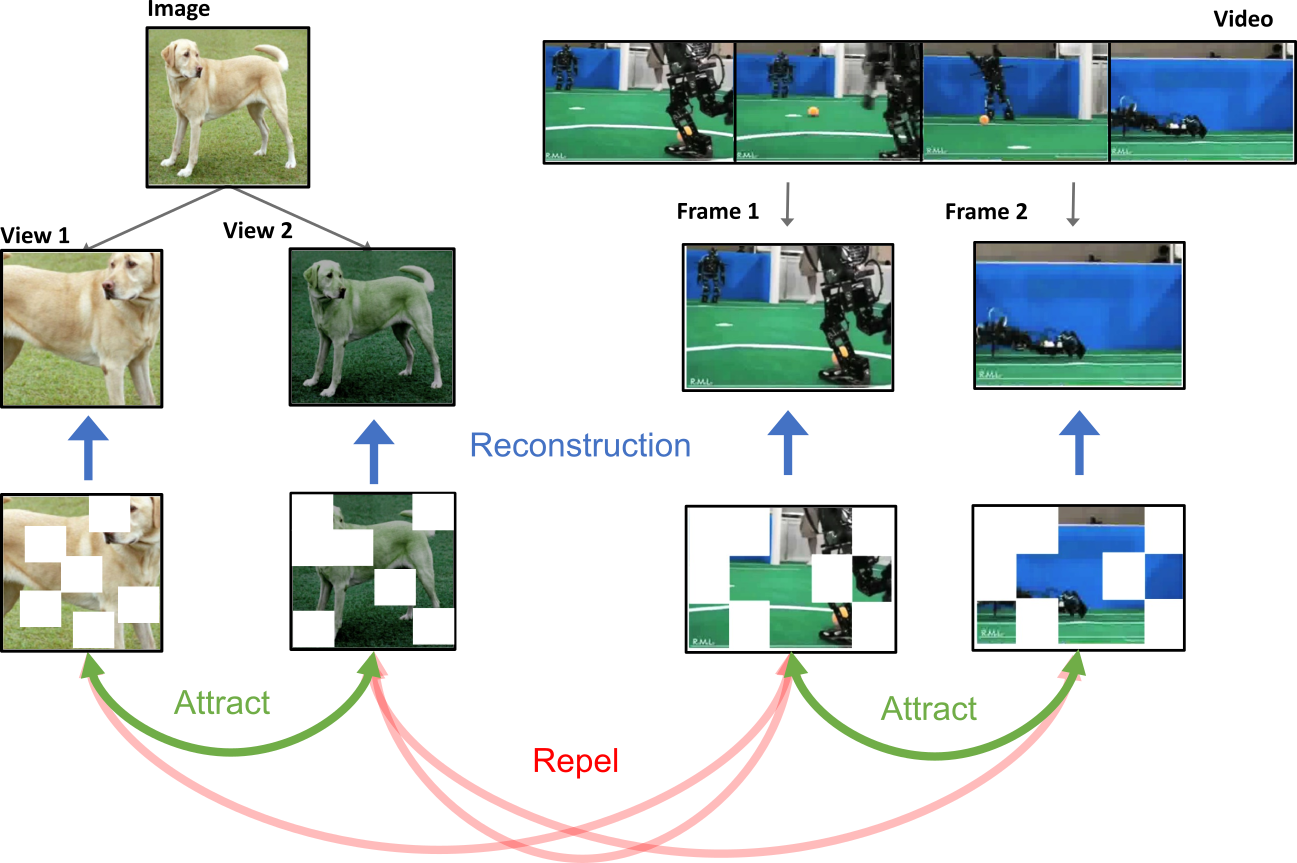
Self-supervised techniques for video representation learning have resulted in considerable success, yielding powerful features that perform well across various downstream tasks. While image-to-video transfer learning has become quite common, resulting in robust video feature representations, the reverse, video-to-image transfer learning, has not been as successful. This discrepancy suggests a potential for improvement in how models trained on video data extract image features.
Learning from video should also yield good image representations since videos naturally contain complex changes in pose, viewpoint, deformations, among others. These variations can not be simulated through the standard image augmentations used in joint-embedding methods or in masked image modeling methods. In this work, we propose a Visual Contrastive Masked AutoEncoder (ViC-MAE), a model that learns from both images and video through self-supervision. Our model improves video-to-image transfer performance while maintaining performance on video representation learning.
Method
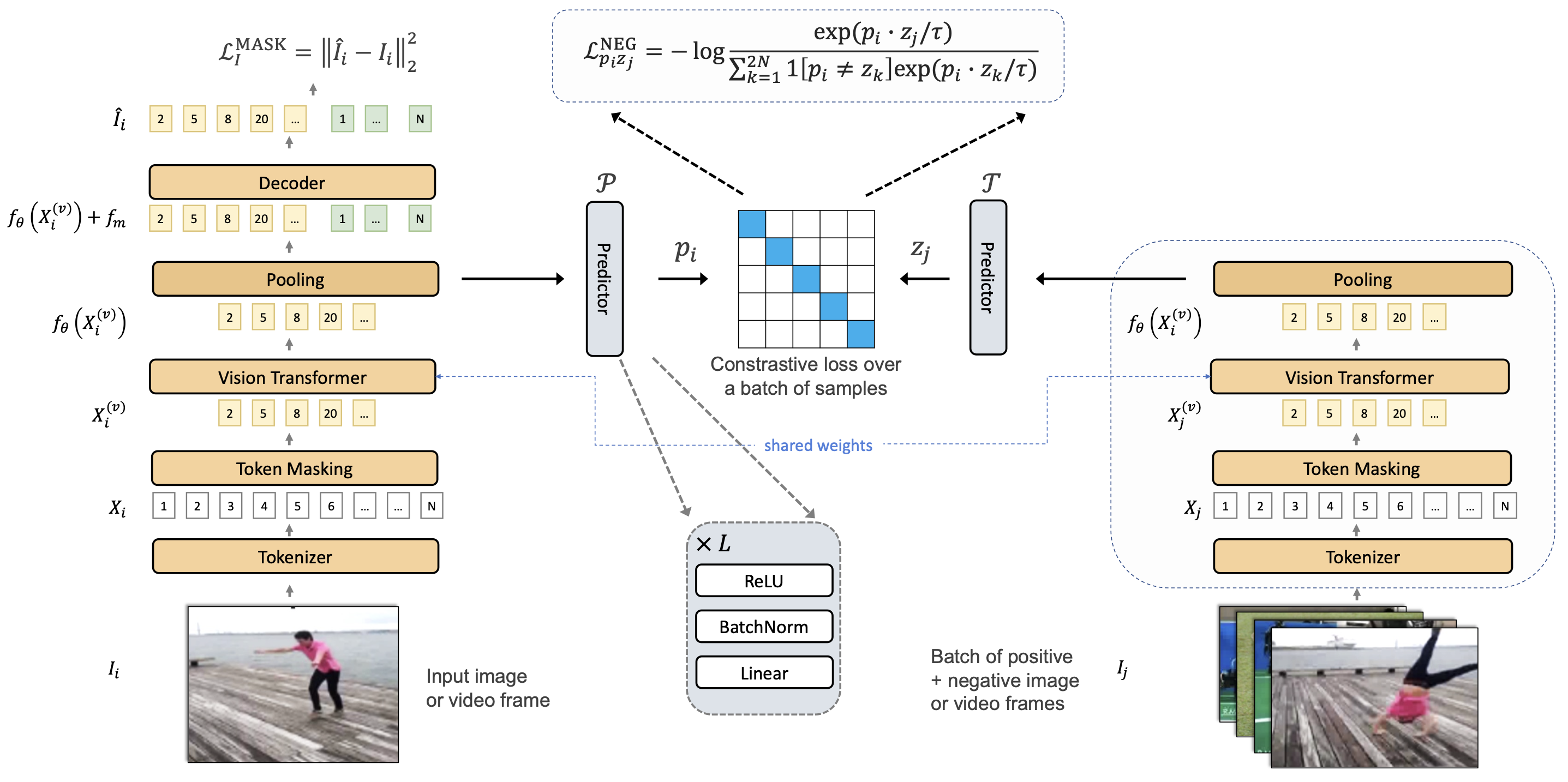
ViC-MAE inputs two distant frames from a video or two different views of an image using a siamese backbone (shared weights), and randomly masks them, before passing them through a ViT model which learns a representation of local features using masked image modeling. A global representation of the video is then constructed by global pooling of the local features learned by the ViT model trained to reconstruct individual patches using an ℓ2 loss. A standard predictor and a target encoder are used with a contrastive loss. Our use of an aggregation layer before the predictor network aids to avoid collapse of the learned global representations.
Experimental Results
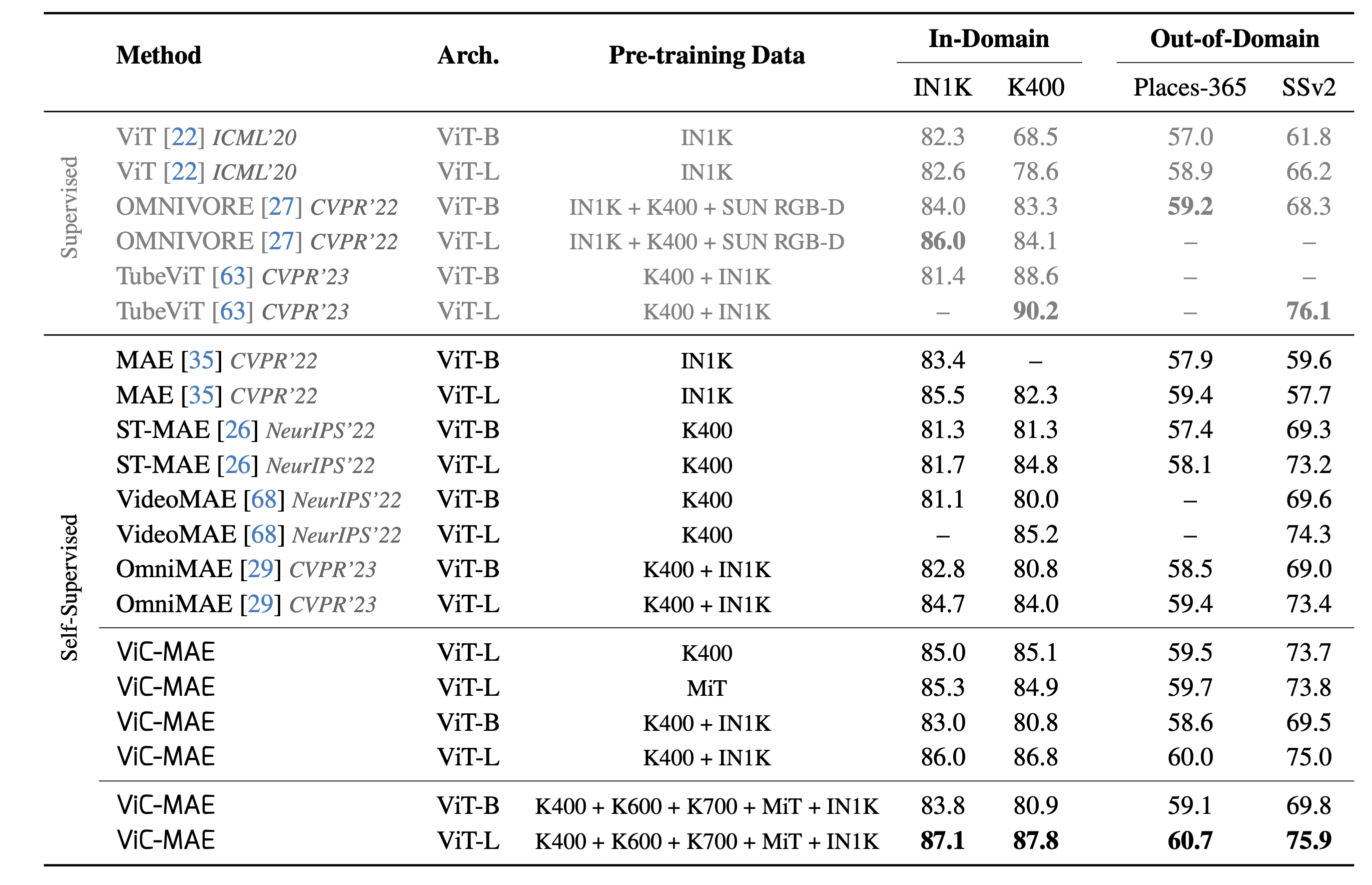
Our main result evaluates ViC-MAE on two in-domain datasets that were used during training for most experiments: ImageNet-1K (images) and Kinetics-400 (video), and two out-of-domain datasets that no methods used during training: Places-365 (images) and Something-something-v2 (video). See table below shows our complete set of results including comparisons with the state-of-the-art on both supervised representation learning (typically using classification losses), and self-supervised representation learning (mostly using masked image modeling). We consider mostly recent methods building on visual transformers as the most recent TubeViT which is the state-of-the-art on these benchmarks relies on this type of architecture. Previous results on the same problem also use different backbones e.g., ResNet-50. They obtain 54.5%, 33.8%, and 55.6% top-1 accuracies on linear evaluation on ImageNet-1k. Since those works are not using the same setting we chose not to include them alongside others.
BibTeX
@article{hernandez2023visual,
title={Visual Representation Learning from Unlabeled Video using Contrastive Masked Autoencoders},
author={Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
journal={arXiv preprint arXiv:2303.12001},
year={2023}}