In this post, we will see how to load a video using PyTorch, followed by a rant on how we perfom evaluations of video models. We will try various methods to load a video and convert it to a PyTorch tensor. These include VideoClips (from torchvision), torchvision.IO (using PyAV), and decord, my own implementation using ffmpeg and FFCV. We will use the Kinetics-400 dataset as an example. You can find the dataset here. All the code is available in this repository. I modified FFCV to be able to handle videos, you can find the fork here.
Video Loading in PyTorch
We explore various approaches to loading the Kinetics-400 dataset, which includes 241,255 training videos and 19,881 validation videos, evaluating them based on speed and resulting dataset size. The methods examined include:
- The standard method, utilizing PyTorch’s VideoClips class for storage. We adopt this approach as a baseline, which involves keeping the videos in their original mp4 format.
- Utilizing torchvision.IO to load the videos. This is a library that uses the torchvision’s VideoReader class and PyAV to load the videos (I was unable to make the new API work see here). This just requires the videos to be stored as mp4 files.
- Employing decord for video loading, a library touted to outpace PyTorch’s VideoReader, with a prerequisite for mp4 format for the videos.
- Implementing the python bindings of ffmpeg for video loading, which also necessitates videos in mp4 format.
- Adopting FFCV , where videos are converted into a sequence of JPEG images. This process involves multiple preprocessing steps: (1) frame extraction from videos, (2) frame resizing to a maximum size, (3) encoding frames as JPEG images, and (4) compiling the frames into a single FFCV file. Opting for JPEG images increases disk space usage but decreases loading times. This approach, as detailed in the ViC-MAE paper, is advantageous for training efficiency, as model feeding speed becomes a critical factor when doing masking autoencoding.
Since videos are most of the time redundat, people usually skip frames when giving them to a neural network. This is ussally denoted as \(T \times t\), where \(T\) is the number of frames the model sees and \(t\) is the number of frames that are skipped in between. We use \(T=16\) and \(t=4\), which is kind of the standard for Kinetics-400. Similarly, for evaluation people usually try to take full coverage of the video, so they split the video into several crops (this can be overlapin or non-overlaping) and average the predictions. Crops are denoted as \(s \times \tau\), where \(s\) is the number of spatial crops and \(\tau\) is the number of time crops. We use 5 time crops an 1 spatial crop, there is no standard and this varies from paper to paper.
Results
Datasets are loaded from RAM, and the time is measured using the time library. We plot the troughput in videos per second.
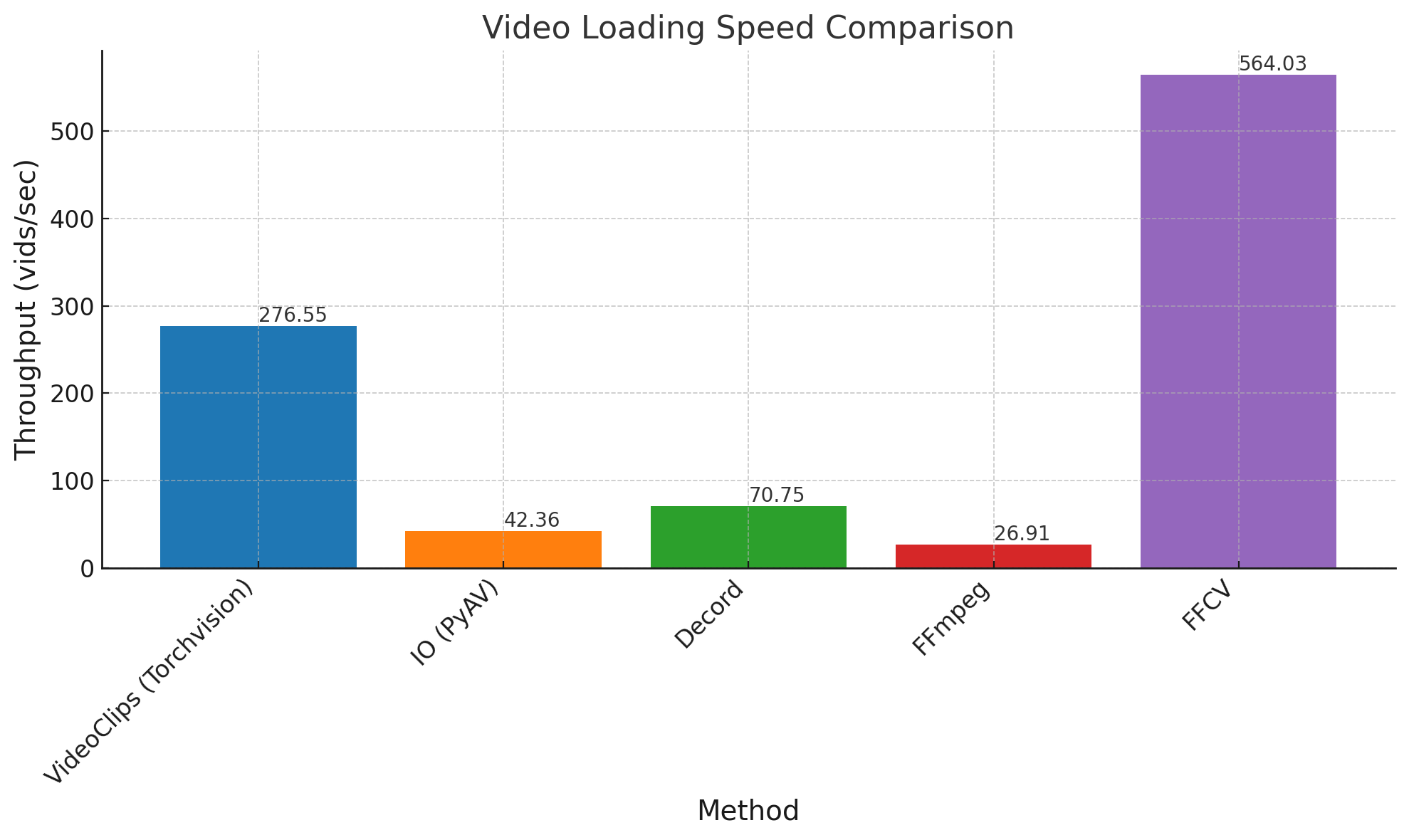
For the standard method a fix cost of prepocessing the dataset i payed and it is approximately 2 hours using 64 cores. But after this the datasets is very versitile it is possible change the FPS of the videos on the fly. This the second fastest method, but it is the most versatile it achieves a troughput of 276.55 videos per second. The slowest method is using ffmpeg, which achieves a troughput of 26.91 videos per second. The second fastest method is using decord, which achieves a troughput of 70.75 videos per second. The third fastest method is using torchvision.IO, which achieves a troughput of 42.36 videos per second. The fastest method is using FFCV, which achieves a troughput of 564.03 videos per second. But since the FFCV approach uses the standar method it has a higher cost of preprocessing the dataset, which is approximately 1 hour using 64 cores. The FFCV approach is the fastest, but it is the most expensive in terms of disk space, it requires 946 GB of disk space to store the training dataset and 44 GB to store the validation dataset. While all the other methods require 348 GB and 29 of disk space to store the training and validation datasets, respectively. The FFCV approach is recomended when you know that you are going to use the dataset in the same configuration several times. The standard method is recomended when your models are not I/O bound, since it is the most versatile. The other methods are simply not recomended, since they are much slower than the standard method.
If you wanted to know how to load videos in PyTorch, I hope this was helpful. If you have any questions or comments, please leave them below. The next is a use case of the FFCV approach, where we evaluate some video models and I use the results to rant about the way we evaluate video models and a call to action to the community for models that handle long videos and harder benchmarks to evaluate them.
Do Kinetics-400 models generalize to other spatial and temporal views?
One question that I have always ponder is what is the best way to evaluate a video model. In image land, think ImageNet-1K, the most common way to evaluate a model is to use a single center crop. You might see people doing Multi-crop at test time techniques, but this is really not common. This is in contrast to video land, where as previously discussed this varies from paper to paper and it varies a lot. Here is a table of some examples:
| Method |
Video frames |
Views |
ViT/B-16 (84M) K400 |
ViT/L-16 (307M) K400 |
| ViC-MAE |
16x4 |
3x7 |
81.5 |
87.8 |
| MaskFeat |
16x4 |
1x10 |
82.2 |
84.3 |
| MViTv1 |
64x3 |
3x3 |
81.2 |
- |
| MViTv1 |
16x4 |
1x5 |
78.4 |
- |
| MViTv1 |
16x4 |
1x10 |
- |
80.5 |
| TimeSformer |
8x4 |
3x10 |
78 |
80.7 |
| ViViT |
32x2 & 32x4 |
1x4 |
79.2 |
81.7 |
| MTV |
16x4 |
3x4 |
81.8 |
84.3 |
| Mformer |
16x4 |
3x10 |
79.7 |
80.2 |
| DINOV1 |
16x4 |
3x10 |
82.5 |
- |
| UMT |
8x2 |
3x4 |
85.7 |
90.6 |
| MVD |
16x4 |
1x10 |
83.4 |
87.2 |
| UniFormerV2 |
8x2 |
3x4 |
85.6 |
- |
| UniFormerV2 |
32x8 |
3x2 |
- |
89.3 |
| Table 1: Examples of video model evaluation on the Kinetics-400 benchmark. |
As we can see numbers are all over the place, and there is no standard. Look at the table and tell me what model is better? I argue that it is kind of hard to tell. Like do we need all those spatial views? If I were to deploy these models wouldnt taking 3 spatial crops make it super slow. On the other end there are models that only need 5 views to see the whole video but take 7 or 10 is that necessary or is it just a way to get better results on the benchmarks? I think that the answer is the latter.
Let’s do an exercise and evaluate some open souce models on Hugging Face using the FFCV approach. But first lets us think what would be a fair evaluation? I think this is not a question with an easy answer, and the current consensus seems to be do what shows best perfomance on the benchmarks. I am guilty of falling into this myself with the ViC-MAE results.
Following similar steps to the image community, indicates that the best most fair way would be a center spatial and a center temporal view. But this is a very strong assumption. Videos are more messy than images, assuming that the action occurs at the center of the video is a very strong assumption, even stronger (to me) than the action occuring at the center of the frame (like in datasets like ImageNet-1K, where given how they were collected this is a reasonable assumption). I am gonna go ahead and for the sake of argument change the evaluation setting to use 1 resize of the whole frame and 5 temporal crops. My reasoning stems that if most models are trained using 16 frames skiping 4 (or 32 skiping 2), you would only need 5 temporal crops to cover the whole video on Kinetics-400 where the average video length is 10 seconds.
The models on the HUB that I found are:
- VideoMAE on the following configurations: Small, Base, Large, Huge. Trained using 16 frames and skipping 4.
- My own ViC-MAE on the following configurations: Base, Large. See the ViC-MAE repository for more details. Trained using 16 frames and skipping 4.
- TimeSformer on the following configurations: Base, HR. Trained using 8 frames and skipping 4 and 16 frames and skipping 4, respectively.
- ViViT on the following configurations: Base. Trained using 32 frames and skipping 2.
You can see the results in table format here. The “View Invariant Accuracy” line is what you would expect if the performance of the models is not affected by a change of view. The results are as follows:
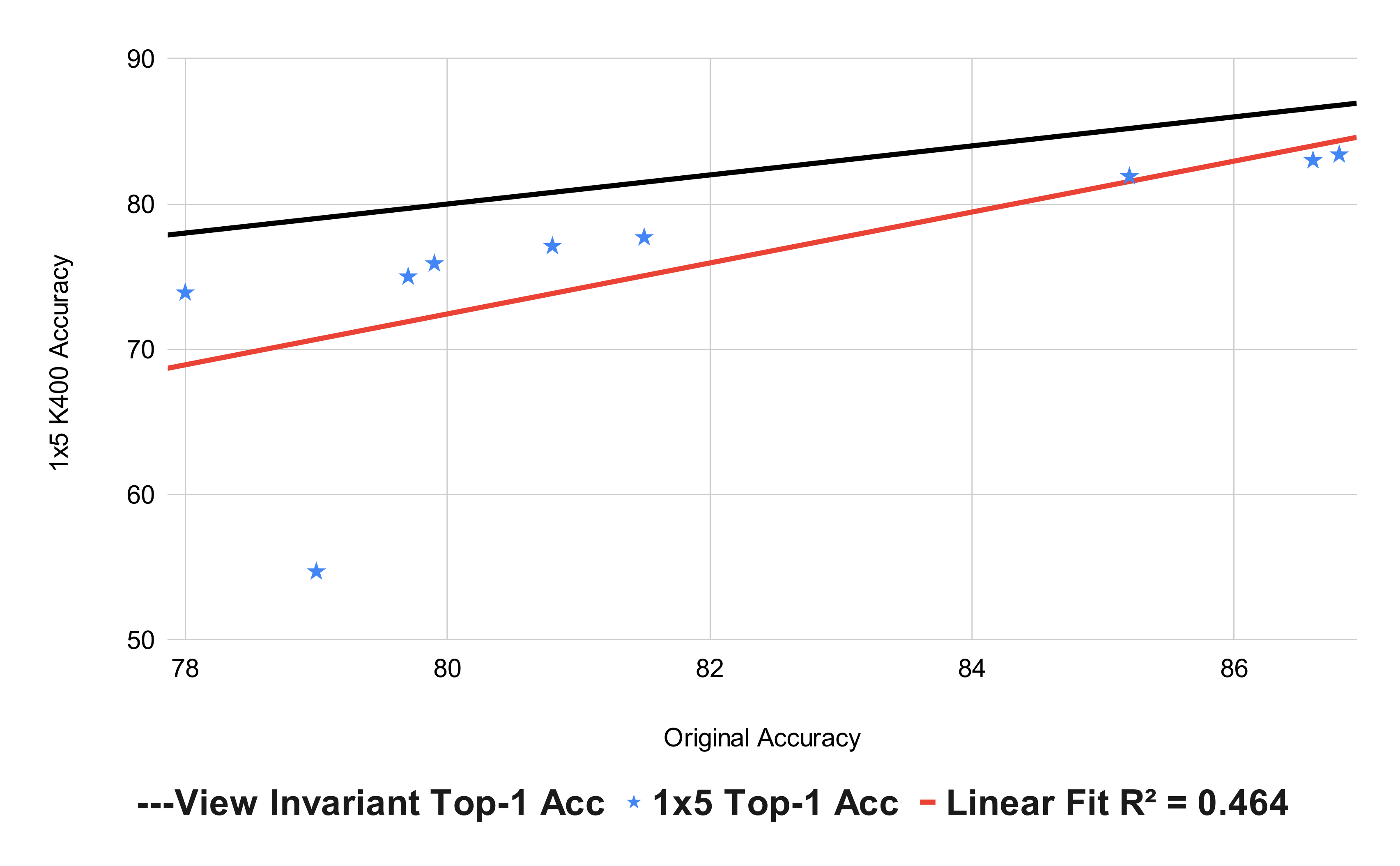
We see a significant drop in accuracy, on average approximately 3%. If you think about it, on 2022 the year VideoMAE came out, the best model was MVT/H with an accuracy of 89.9%, if we assume the trend holds that means an accuracy drop to approximately 86% when chaging views or almost a year of progress. You should not take this as a criticism of the models, the work that the authors did is amazing and I am a big fan of their work. But I think that this is a criticism of the way we evaluate video models.
When calculating a linear fit (using very few data points, I know, sue me!) over the original accuracies of the models and their new accuracies, we get:
\[\begin{aligned}
\text{acc}_{\text{new}} &= 1.75 \cdot \text{acc}_{\text{orig}} - 67.8 \\
\end{aligned}\]
The slope greater than 1 indicates that as models get better accuracies they become more invariant to view changes. You can also interpret this as bigger models are more invariant to view changes, since larger models are usually the best. We can see the most egregious example of this on the smallest model (VideoMAE/S-16) that sees a dramatic drop of more than 20% points in accuracy. In general, we expect the largest and better models to be more invariant to view changes, think InternVideo and VideoMAE V2-g that both cross the billion parameter mark and get >90% accuracies.
Why is this important?
In general, I think that using spatiotemporal views in video models is a way to compensate for the fact that our models can not see more than a few seconds of video and can not handle large frame resolutions. We dont know where an action is happening and when it is happening, so as a proxy we evaluate our models in all posible partitions and compute a result over these partitions. But is this what we really want our models to do?
Drawing inspiration from image land, where we have models that can tell me where an object is and what object it is for almost reasonable arbitrary image resolutions. It would seem that we want a model that takes video of abritary length and resolution and outputs what is happening, where it is happening and when it is happening. This is a very (emphasis on very) hard problem, but I think that this is what we ultimately want our models to do. I think this not what we currently are doing on part because it is truly hard and also on part because of the do what shows best perfomance on the benchmarks mentality.
Given that the what, where and when problem is really really hard, a reasonable start should be to just focus on the what and when, this problem is called “temporal action localization”. Is someone working on this? A lot of people it seems and their works are amazing, you should definitely check them out.
But if you go to papers with code the most active dataset seems to be THUMOS’14 a small dataset with ~1500 examples and where our best models get 75% mAP. While bigger datasets like ActivityNet-1.3, HACS, EPIC-KITCHENS-100 and FineAction seem to get less attention and our best models dont even cross the 50% mAP.
Finally, I also want to argue that we need more video models that can handle long videos, if you look a the best results on those benchmars you will se that our best models are basically partioning the videos into small segments, using a regular short term video model (like VideoMAE) to extract features and then working on those features to get the final result. I think a more end-to-end approach is needed, and that it would provide better results.
Conclusion
In conlusion, we have seen various methods to load videos on PyTorch, and that you can load your videos 2X faster if you are willing to sacrifice a little of flexibility and a lot disk space. I, then, used this as an excuse to rant about the way we evaluate video models and the direction that I think we should be heading. In my opinion, the field needs more models that can handle long videos and harder benchmarks to evaluate them. I hope you enjoyed this post, and that you learned something new. If you have any questions or comments, please leave them below.
comments powered by